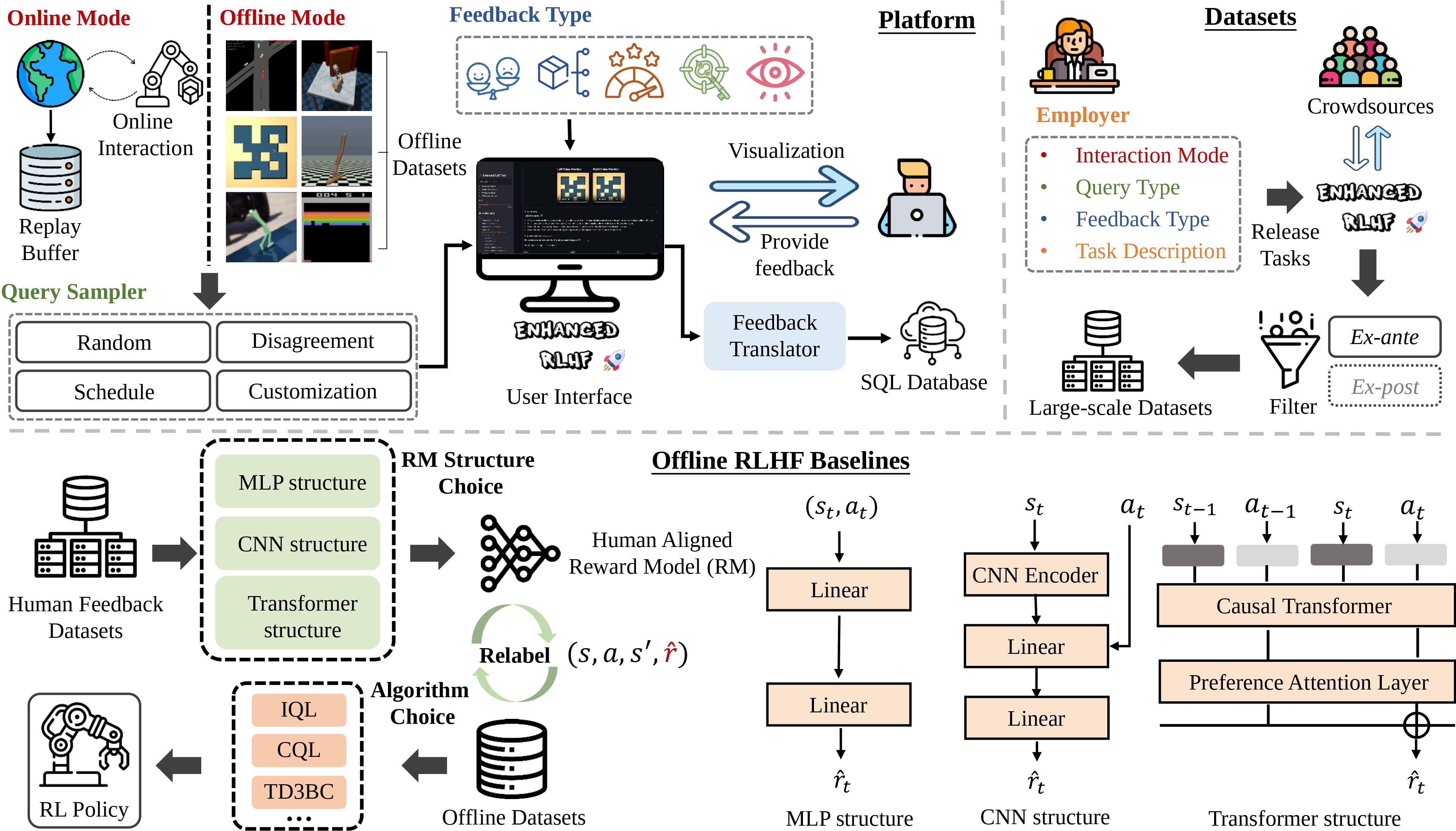
Reinforcement Learning with Human Feedback (RLHF) has received significant attention for performing tasks without the need for costly manual reward design by aligning human preferences. It is crucial to consider diverse human feedback types and various learning methods in different environments. However, quantifying progress in RLHF with diverse feedback is challenging due to the lack of standardized annotation platforms and widely used unified benchmarks. To bridge this gap, we introduce Uni-RLHF, a comprehensive system implementation tailored for RLHF. It aims to provide a complete workflow from real human feedback, fostering progress in the development of practical problems. Uni-RLHF contains three packages: 1) a universal multi-feedback annotation platform, 2) large-scale crowdsourced feedback datasets, and 3) modular offline RLHF baseline implementations. Uni-RLHF develops a user-friendly annotation interface tailored to various feedback types, compatible with a wide range of mainstream RL environments. We then establish a systematic pipeline of crowdsourced annotations, resulting in large-scale annotated datasets comprising more than 15 million steps across 32 popular tasks. Through extensive experiments, the results in the collected datasets demonstrate competitive performance compared to those from well-designed manual rewards. We evaluate various design choices and offer insights into their strengths and potential areas of improvement. We wish to build valuable open-source platforms, datasets, and baselines to facilitate the development of more robust and reliable RLHF solutions based on realistic human feedback.
To align RLHF methodologies with practical problems and cater to researchers’ needs for systematic studies of various feedback types within a unified context, we introduce the Uni-RLHF system. We start with the universal annotation platform, which supports various types of human feedback along with a standardized encoding format for diverse human feedback. Using this platform, we have established a pipeline for crowdsourced feedback collection and filtering, amassing large-scale crowdsourced labeled datasets and setting a unified research benchmark.
 The Uni-RLHF supports both online and offline training modes. Some representative tasks from these environments are visualized above.
Furthermore, Uni-RLHF allows easy customization and integration of new offline datasets
by simply adding three functions.
The Uni-RLHF supports both online and offline training modes. Some representative tasks from these environments are visualized above.
Furthermore, Uni-RLHF allows easy customization and integration of new offline datasets
by simply adding three functions.
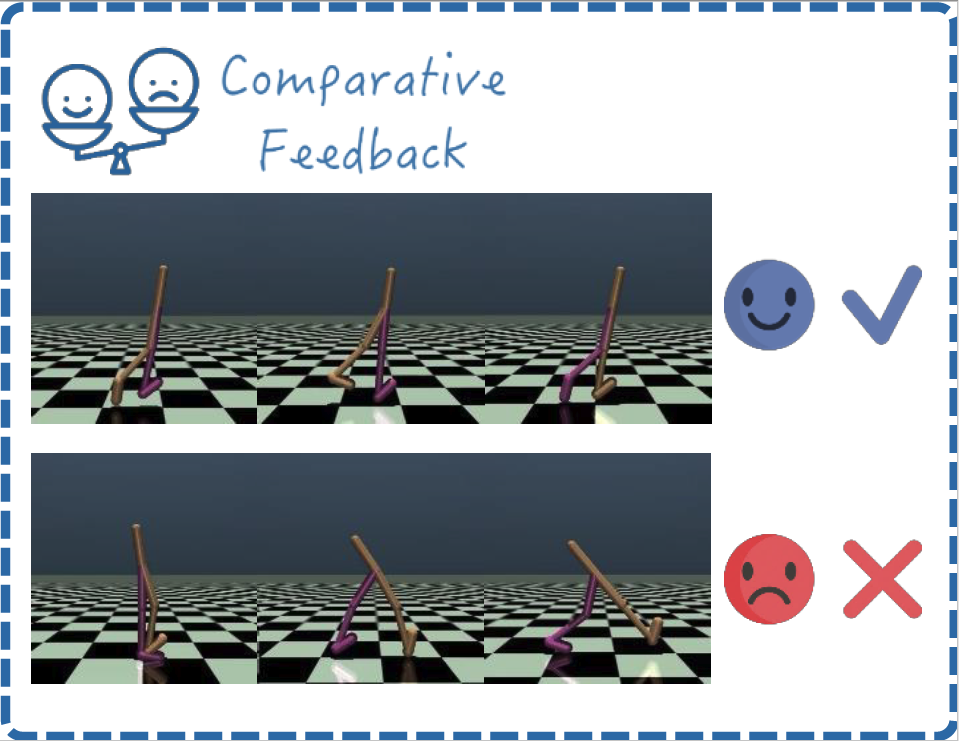
Comparative Feedback
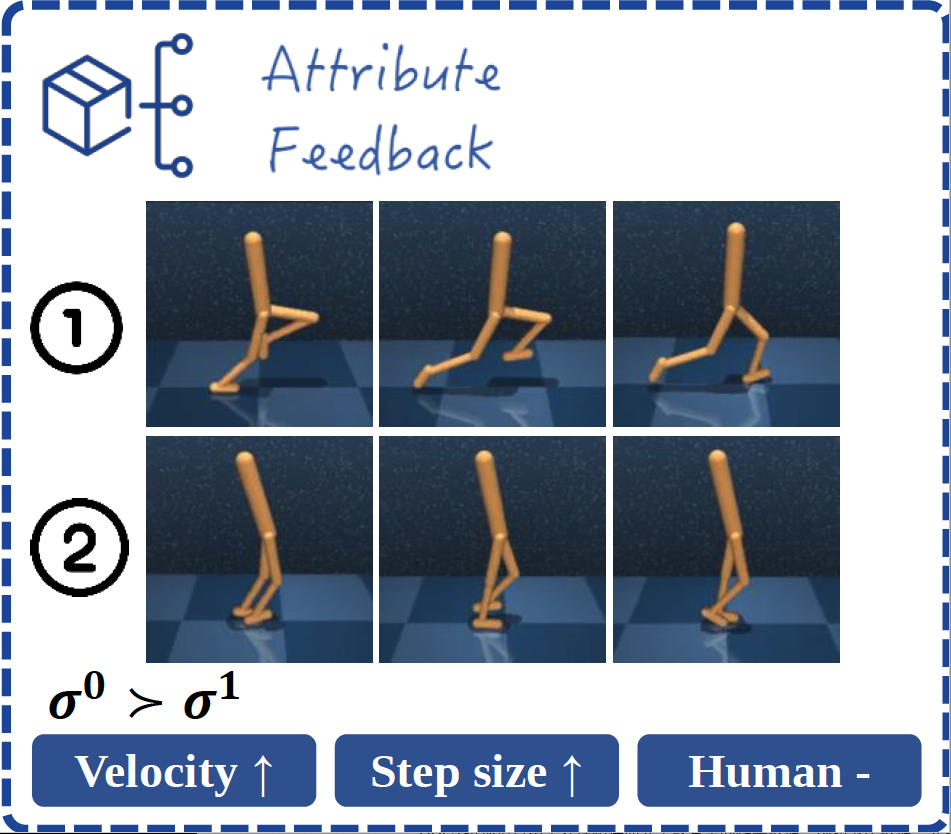
Attribute Feedback

Evaluative Feedback
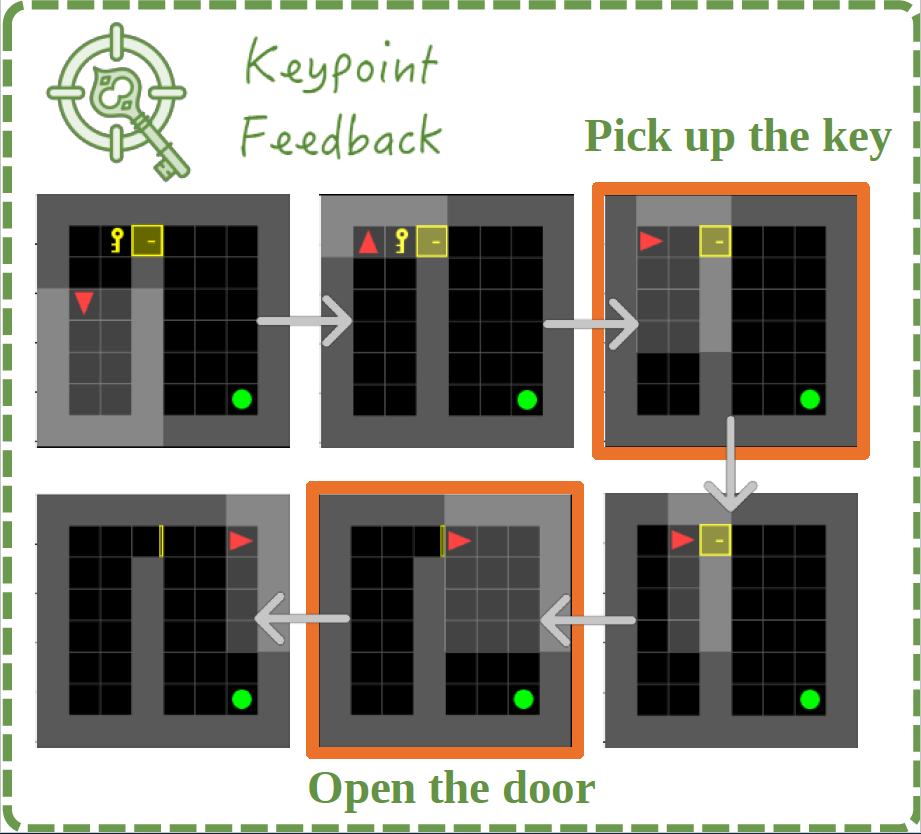
Keypoint Feedback
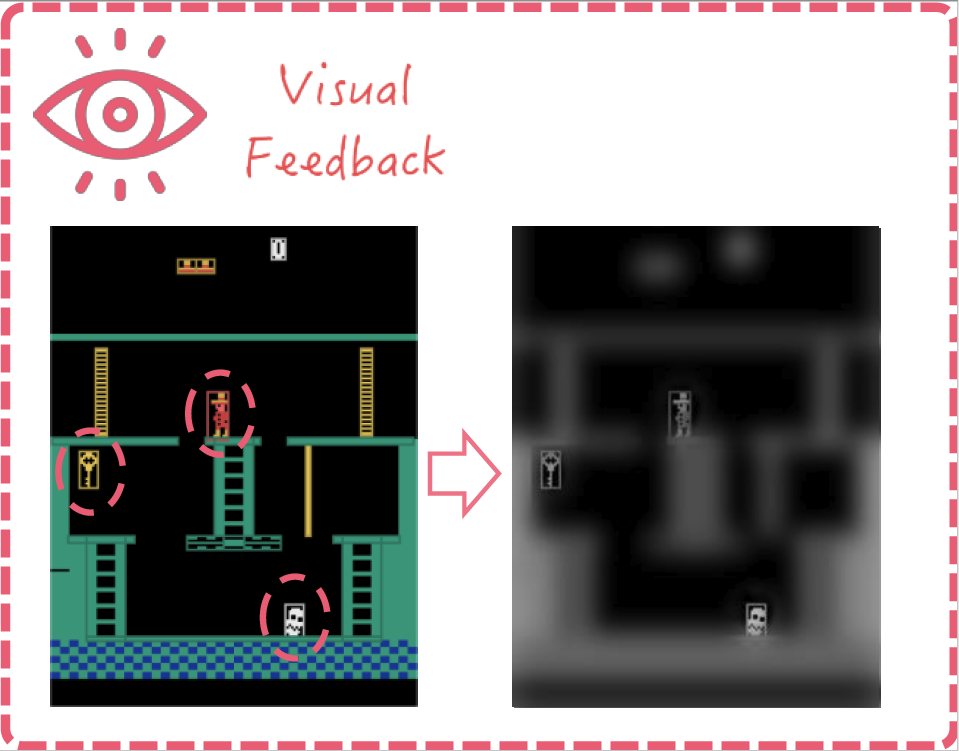
Visual Feedback
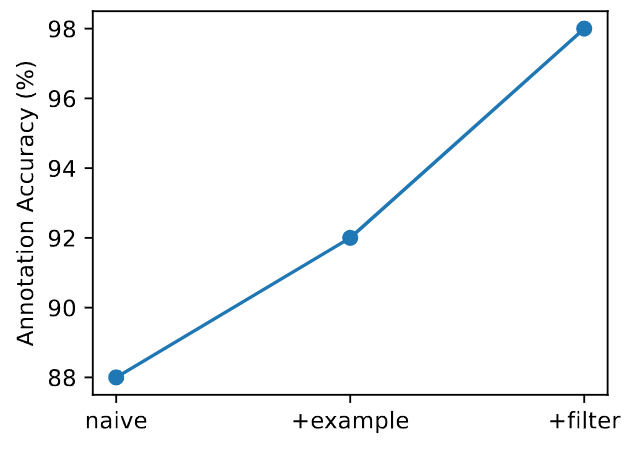 The effectiveness of each component in the annotation pipeline. We initially sampled 300
trajectory segments of the left-c task in SMARTS for expert annotation, referred to as Oracle.
We had five crowdsourcing instances, each annotating 100 trajectories in three distinct settings.
naive implies only seeing the task description, +example allows for viewing five expert-provided annotation
samples and detailed analysis, and +filter adds filters to the previous conditions. The experimental results
displayed in above, revealed that each component significantly improved annotation accuracy, ultimately achieving a 98% agreement rate
with the expert annotations.
The effectiveness of each component in the annotation pipeline. We initially sampled 300
trajectory segments of the left-c task in SMARTS for expert annotation, referred to as Oracle.
We had five crowdsourcing instances, each annotating 100 trajectories in three distinct settings.
naive implies only seeing the task description, +example allows for viewing five expert-provided annotation
samples and detailed analysis, and +filter adds filters to the previous conditions. The experimental results
displayed in above, revealed that each component significantly improved annotation accuracy, ultimately achieving a 98% agreement rate
with the expert annotations.
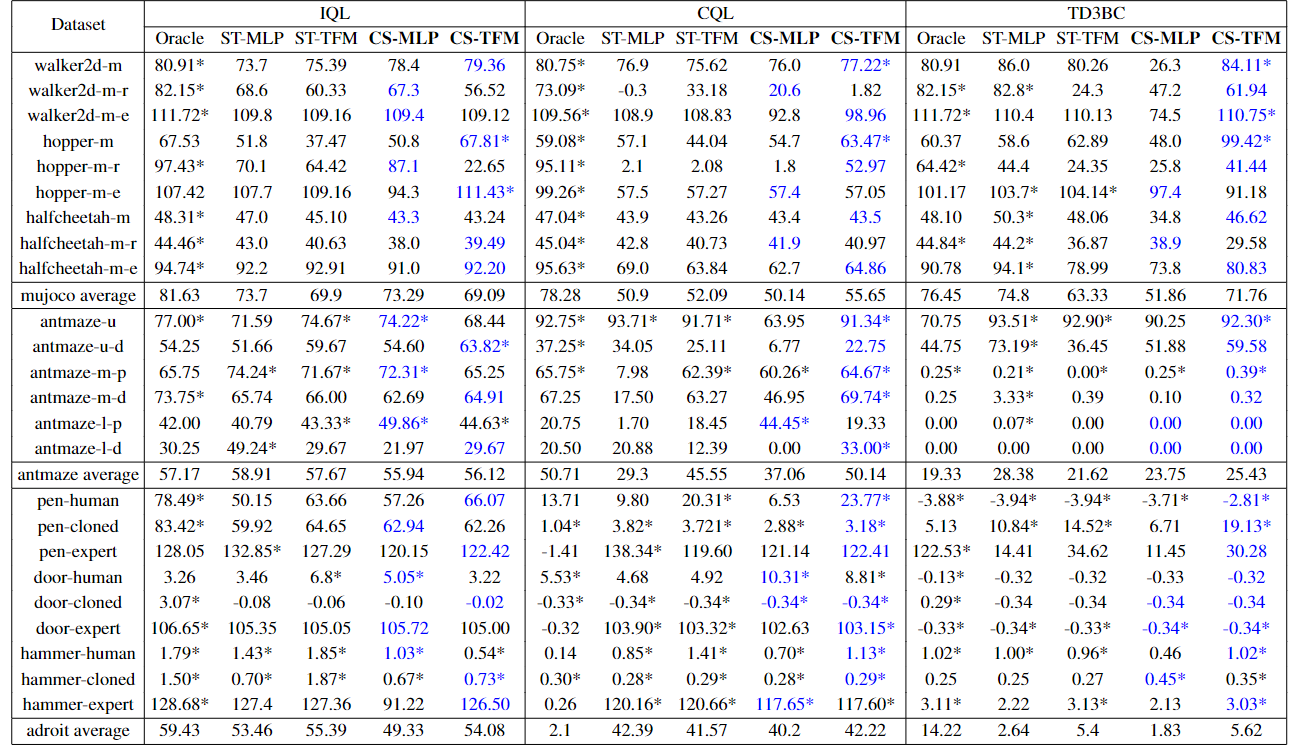
Finally, we conducted numerous experiments on downstream decision-making tasks, utilizing the collected crowdsourced feedback datasets to verify the reliability of the Uni-RLHF system.
Left_c
Cutin
Cruise
Oracle model (left) and our CS model (right) for three scenarios in autonomous driving
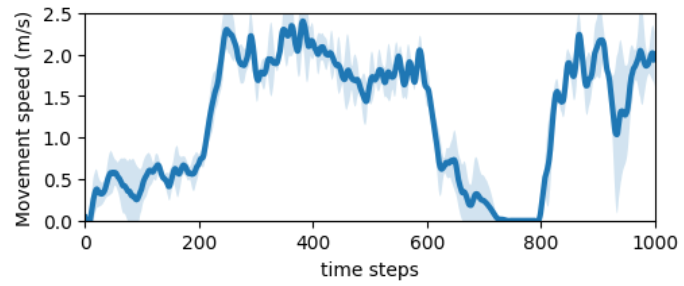
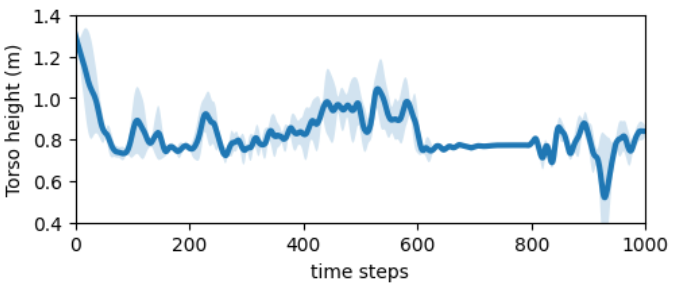
We validate the effectiveness of the online mode of Uni-RLHF, which allow agents to learn novel behaviors where a suitable reward function is difficult to design. Finally, we give totally 200 queries of human feedback for walker front flips experiments and we observe that walker can master the continuous multiple front flip fluently.
Annotation
Create Task
@inproceedings{yuan2023unirlhf,
title={Uni-{RLHF}: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback},
author={Yuan, Yifu and Hao, Jianye and Ma, Yi and Dong, Zibin and Liang, Hebin and Liu, Jinyi and Feng, Zhixin and Zhao, Kai and Zheng, Yan}
booktitle={The Twelfth International Conference on Learning Representations, ICLR},
year={2024},
url={https://openreview.net/forum?id=WesY0H9ghM},
}